Как выбрать часы: зануд системный подход с использованием современных аналитических средств
Вступление
Часто работа аналитика данных начинается с этапа их сбора и подготовки. Здесь работает принцип Парето 80/20. Если зачастую в машинном обучении 80% времени занимает подготовка данных и лишь 20% – само машинное обучение, то в аналитике данных порой складывается ситуация, когда 80% времени занимаемся сбором данных и инженерией, и лишь 20% остаются на манипулирование.
Говорят, на этом графике где-то потерялось еще 50% на рисование схем, сводных таблиц и дашбордов, но это не точно…
Одно из направлений сбора данных – собирать данные с веб-сайтов. Такой процесс называют парсинг (parsing) или веб-скрапинг (webscraping).
Выполнять парсинг сайтов можно на любых языках программирования и даже с помощью специализированных no-code и low-code платформ. Часто можно услышать о парсинге с использованием Python и специализированных библиотек beautifullsoap, scrapy и др.
В данной статье я покажу как это можно сделать с использованием R.
Задача
Составить сводную таблицу с характеристиками часов G-Shock, которая облегчит их сравнение между собой.
Сбор данных
Если зайти на официальный сайт https://www.g-shock.eu, и немного в браузере его поисследовать, то можно обнаружить, что у каждой модели часов есть своя страница и на ней есть переключатели с характеристиками часов и их подробным описанием.
Среди наиболее известных инструментов скрапинга Scrapy, Storm Crawler, River Web и Nutch.
Проблема в том, что для сравнения придется прощелкивать все странички со всеми часами. Наша задача –автоматизировать данный процесс.
Для начала получим список всех моделей часов.
Собираем список всех существующих часов
По адресу https://www.g-shock.eu/ru/watches/ есть встроенный настраиваемый фильтр. Включим отображение всех доступных часов.
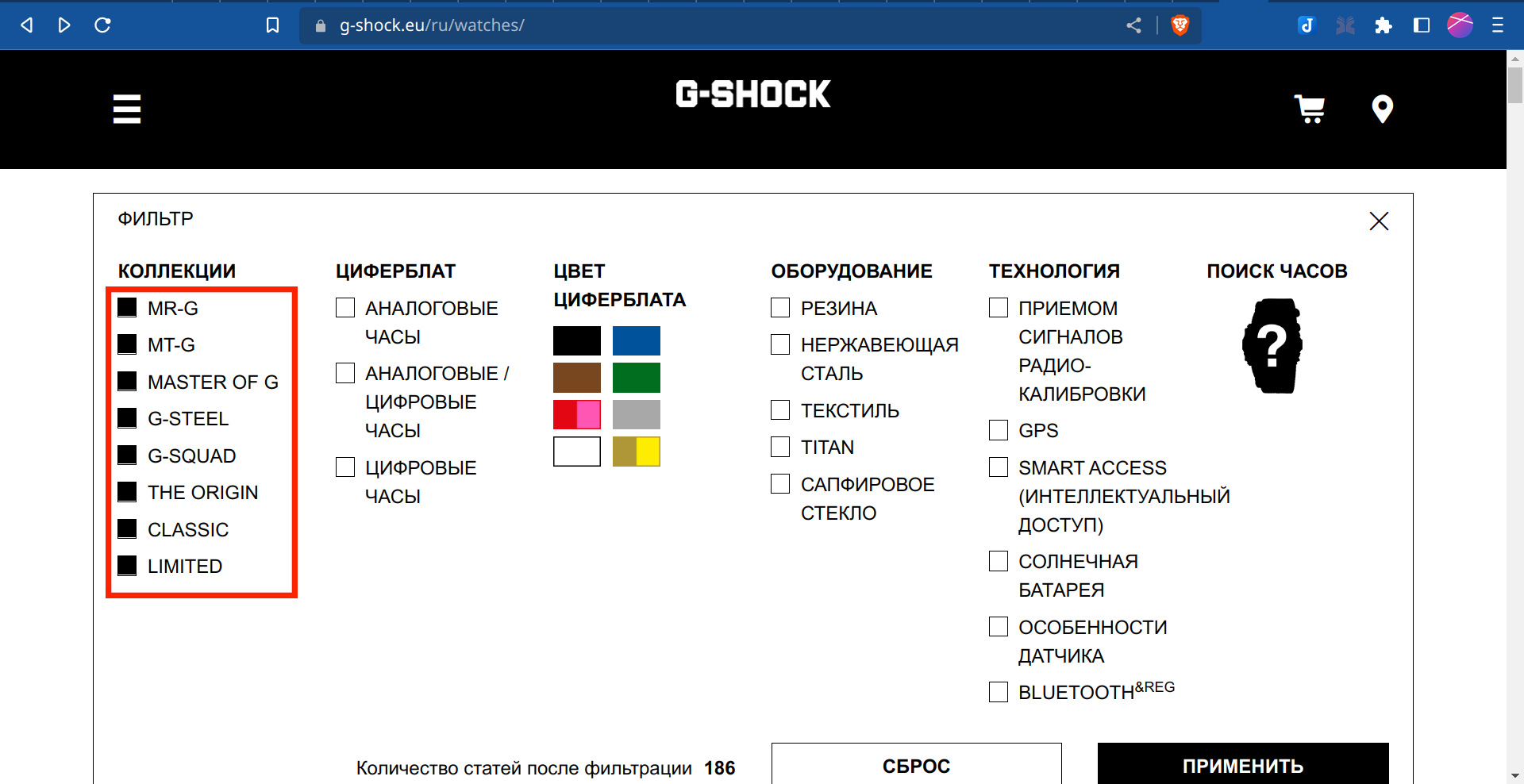
В строке браузера увидим,что ссылка на такую страницу стала выглядеть как https://www.g-shock.eu/ru/watches/filter-mrg-mtg-masterofg-gsteel-gsquad-theorigin-classic-limited/.
Теперь из такой страницы мы сможем извлечь все названия моделей часов и ссылки на индивидуальные страницы которые потом будем парсить для сбора характеристик.
Приступим!
Получаем страницу
В R за парсинг веб-страниц отвечает пакет rvest, который входит в состав метапакета tidyverse.
Для начала получим страницу, которую мы смотрели в браузере:
library(tidyverse)
gurl <- "https://www.g-shock.eu/ru/watches/filter-mrg-mtg-masterofg-gsteel-gsquad-theorigin-classic-limited/"
p <- rvest::read_html(gurl)Теперь нам надо найти ссылки на индивидуальные страницы моделей часов. Для этого будем использовать встроенные в браузер инструменты разработчика.
Ищем нужный элемент страницы
В браузере щелкаем правой кнопкой мыши на ссылке на любую модель часов и выбираем Просмотреть код.
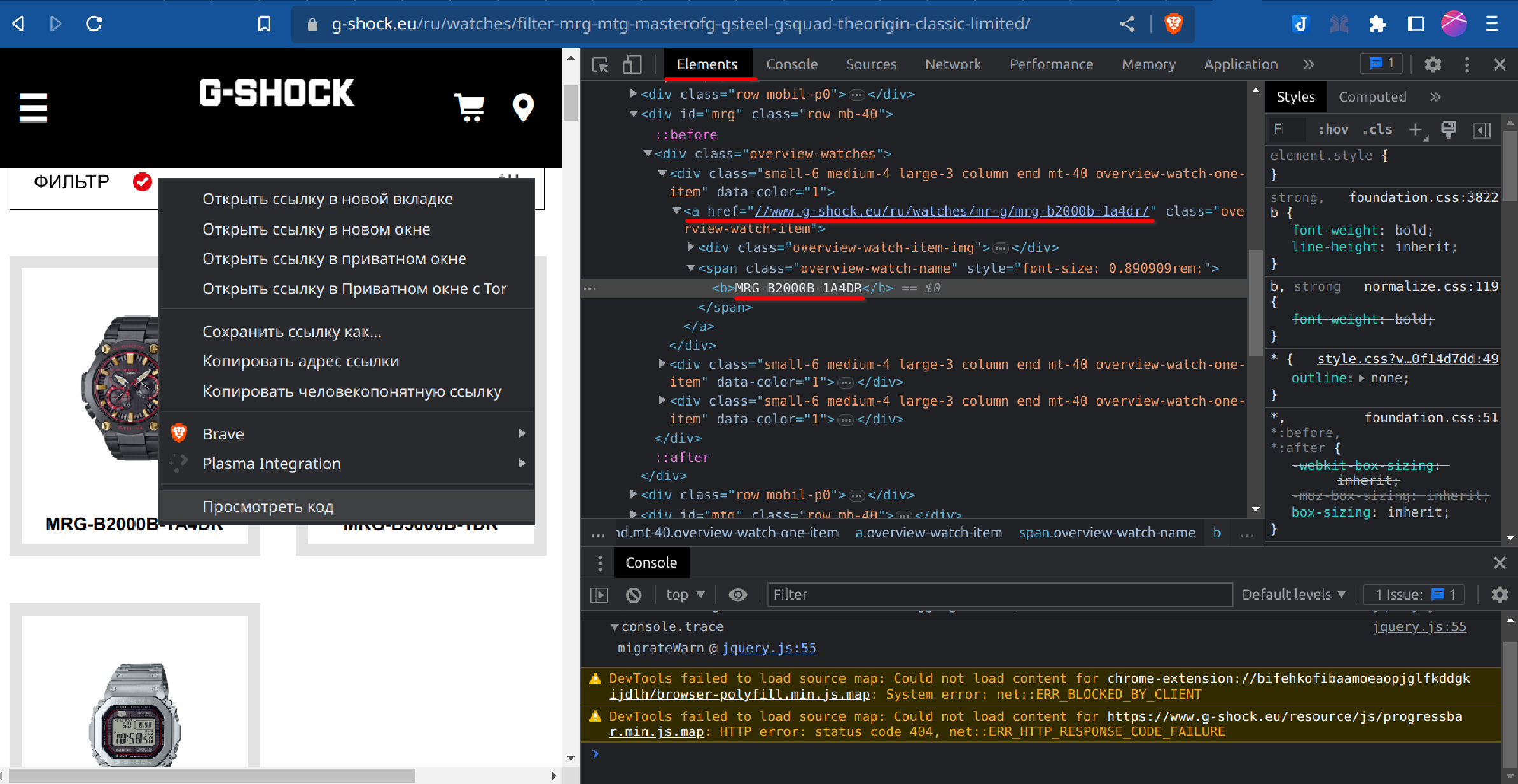
На вкладке Elements видим HTML код веб-страницы.
В принципе, можно даже глубоко не погружаться в него – мы знаем, что ссылки в HTML выглядят как <a href="mail.ru"></a>. Найдем все ссылки в документе и возьмем значение атрибута href.
lnks <- p %>%
rvest::html_elements("a") %>%
rvest::html_attr("href")Отфильтруем ссылки
Можно заметить, что ссылки, ведущие на страницы часов содержат фрагмент /ru/watches/. Отфильтруем и положим в тибл(tibble):
watch_lnks <- lnks[grep("/ru/watches/", lnks)]
dfw <- tibble(links = watch_lnks)Однако, в наш список попали и ссылки на серии часов, например //www.g-shock.eu/ru/watches/classic/. Выбросим все строки, в которых слешей (/) меньше 7:
# применим функцию подсчета символа к каждому элементу dfw$links
n_slash <- lapply(dfw$links, stringr::str_count, "\\/")
# добавим новый столбец в dfw из переменной n_slash (которая имеет тип list)
dfw$n_slash <- n_slash
# оставим только те значения, которые больше или равны 7
wlinks <- dfw %>%
filter(n_slash >= 7) %>%
mutate(wurl = paste0("https:",links)) # допишем https: Список ссылок на индивидуальные страницы готов! Всего получилось 184 модели.
wlinks$wurl %>% head()[1] "https://www.g-shock.eu/ru/watches/mr-g/mrg-b2000b-1a4dr/"
[2] "https://www.g-shock.eu/ru/watches/mr-g/mrg-b5000b-1dr/"
[3] "https://www.g-shock.eu/ru/watches/mr-g/mrg-b5000d-1dr/"
[4] "https://www.g-shock.eu/ru/watches/mt-g/mtg-b3000d-1aer/"
[5] "https://www.g-shock.eu/ru/watches/mt-g/mtg-b3000b-1aer/"
[6] "https://www.g-shock.eu/ru/watches/mt-g/mtg-b3000bd-1a2er/"Собираем характеристики модели
Теперь нам нужно научиться извлекать характеристики каждой модели часов. Поисследуем в браузере какую-нибудь страницу.
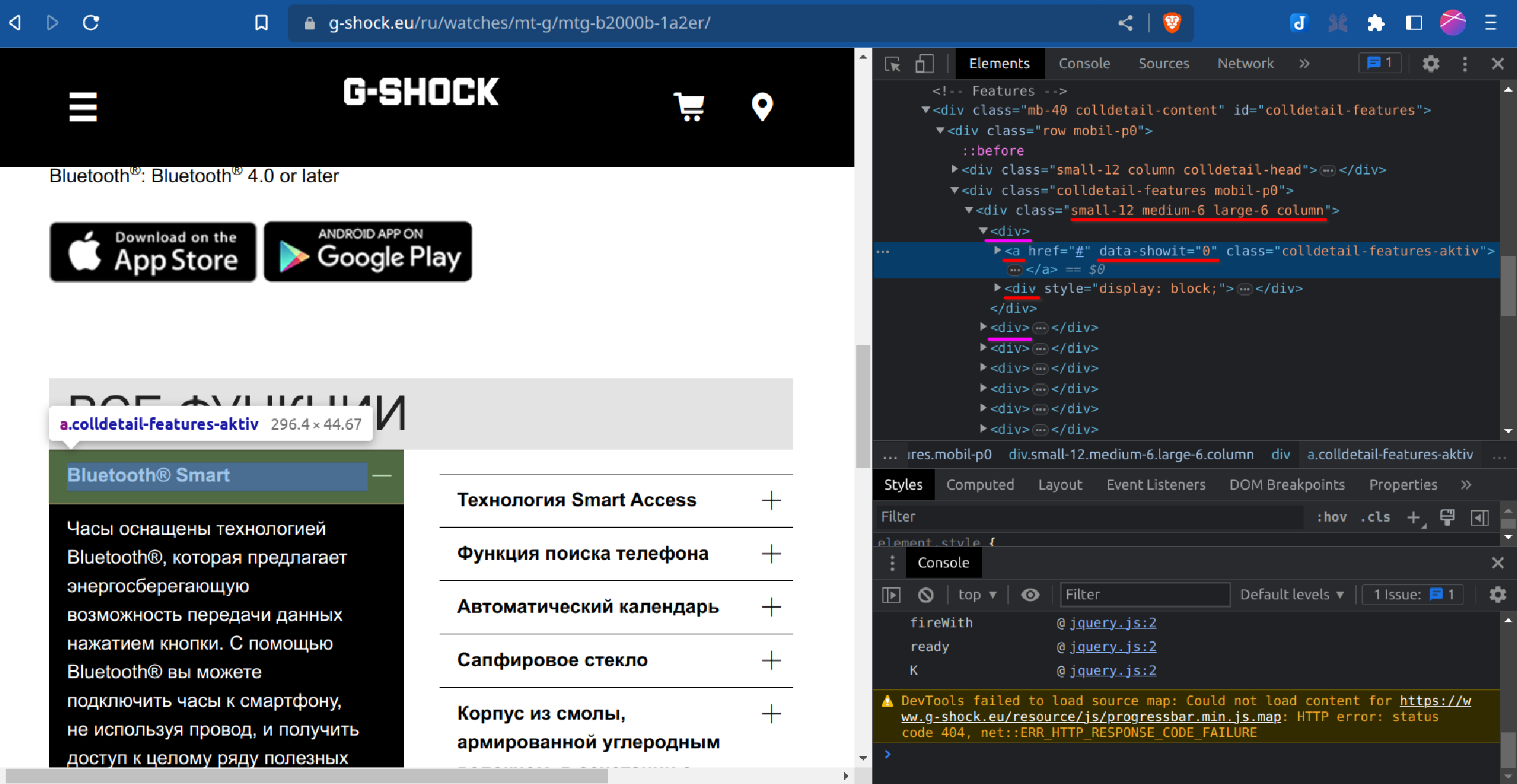
Находим на странице раздел “Все функции”, выбираем любую, жмем правую кнопку мыши, Просмотреть код.
Ищем элементы на странице
Заметим, что каждая характеристика (например, Bluetooth Smart) в HTML коде выглядит как блок, обрамленный тегами <div>. Все характеристики вложены в <div class="small-12 medium-6 large-6 column">:
<div class="small-12 medium-6 large-6 column">
<div>
<a href="#" data-showit="0" class="colldetail-features-aktiv">Bluetooth® Smart... </a>
<div style="display: block;">Часы оснащены...</div>
</div>
</div>Рассмотрим поподробнее. Внутри такого блока есть 2 подблока:
- блок
<a>c атрибутомdata-showit="0", который содержит название характеристики (Bluetooth® Smart); - вложенный блок
<div>с описанием, либо значением характеристики (Часы оснащены…).
Используем XPATH
Искать будем через XPATH – технологию адресации элементов в HTML и XML документах.
Функция извлечения характеристик со страницы будет выглядеть так:
get_watch_df <- function(watch_url){
cli::cli_alert_info(paste("Get", watch_url))
Sys.sleep(3) #Задержка для исключения возможного бана из-за потока запросов
p <- rvest::read_html(watch_url)
attrs <- p %>%
rvest::html_elements(xpath = '//a[@data-showit="0"]') %>%
rvest::html_text(trim = TRUE)
descr <- p %>%
rvest::html_elements(xpath = '//div[@class="small-12 medium-6 large-6 column"]/div/div') %>%
rvest::html_text(trim = TRUE)
watch_df <- tibble::tibble(name = attrs,
value = descr)
return(watch_df)
}В конструкции
rvest::html_elements(xpath = '//a[@data-showit="0"]')мы ищем элемент по запросу: “Элемент с тегом a, имеющий атрибут data-showit равный 0”. Далее, у найденного элемента мы считываем текст, попутно удаляя возможные лишние пробелы (trim) – rvest::html_text(trim = TRUE).
В следующей конструкции
rvest::html_elements(xpath = '//div[@class="small-12 medium-6 large-6 column"]/div/div')логика поиска элемента следующая: “Внутри элемента div, имеющего атрибут class="small-12 medium-6 large-6 column", нужно найти вложенный div, а в нем – еще один вложенный”. И также вытаскиваем текстовое значение.
Масштабируем…
Запустим для всех моделей через map:
purrr::map

library(purrr)
res_df <- purrr::map(wlinks$wurl, get_watch_df)Данные собраны!
Готовим сводную таблицу
В переменной res_df у нас находится объект типа list, элементами которого являются датафреймы (тиблы) с характеристиками. Для 184 ссылок на страницы часов мы имеем 184 соответствующие таблицы с характеристиками, при этом их порядковые номера совпадают.
Поэтому можно просто объединить список ссылок и список датафреймов. Хотя, если подумать, ссылки нам больше не нужны – зато нужны просто названия часов. Предварительно удалим общую часть ссылки:
wlinks <- wlinks %>%
mutate(wnames = stringr::str_replace(links, "//www.g-shock.eu/ru/watches/", ""))
df <- tibble::tibble(watch = wlinks$wnames,
features = res_df)Раскроем вложенные датафреймы
В экосистеме tidyverse есть пакет tidyr для продвинутого манипулирования данными в парадигме tidy data – аккуратных данных.
О концепции tidy data можно подробнее узнать здесь на английском и здесь на русском
Уберем вложенность с помощью функции unnest_wider(), а затем с помощью separate_rows() разделим столбцы name и value на строки по разделителю ’ ,’. Также, можно сразу удалить пустые строки name :
unnest_wider()

separate_rows()
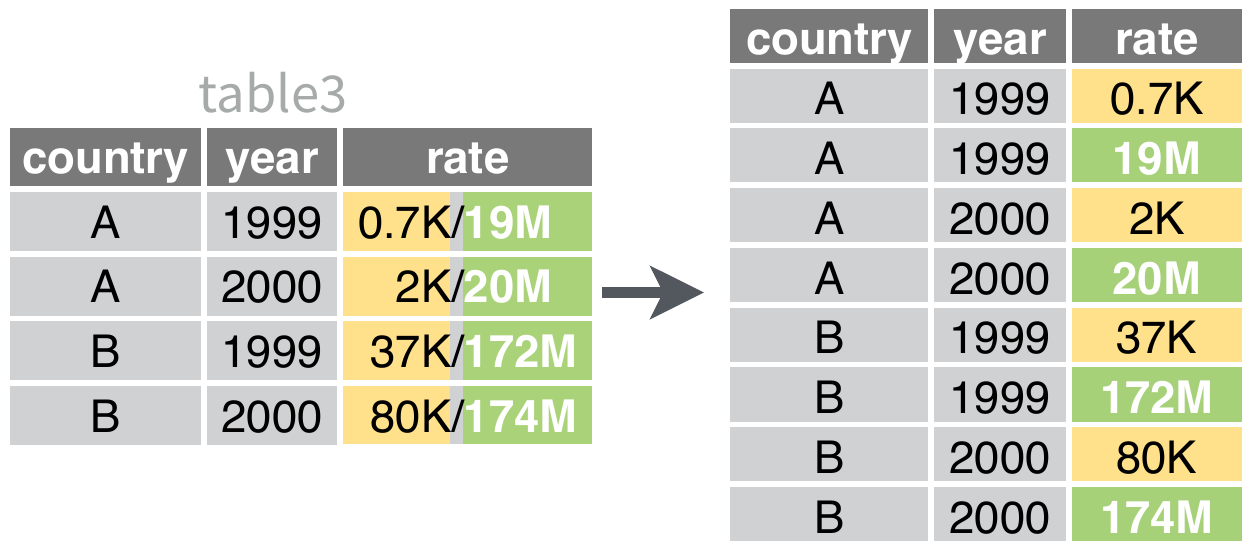
df <- tidyr::unnest_wider(df, features) %>%
tidyr::separate_rows(`name`,`value`, sep = ' ,') %>%
filter(`name` != "")Наконец, приведем к виду “аккуратных данных”, где каждая строка – отдельное наблюдение (модель часов), а столбцы – признаки (отдельные характеристики):
pivot_wider
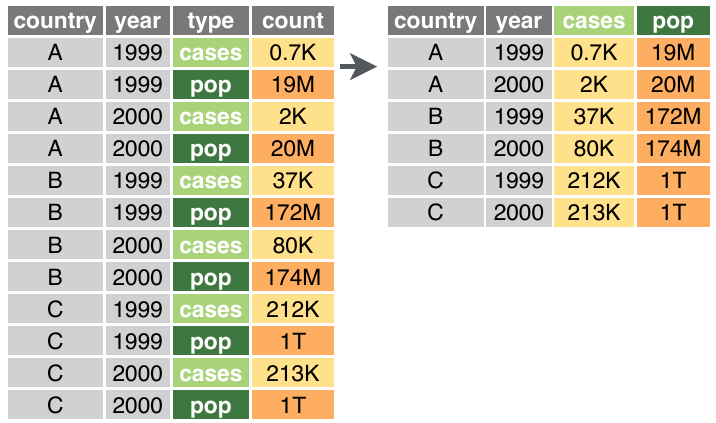
df <- df %>% tidyr::pivot_wider(names_from = `name`, values_from = `value`)Сделаем тибл красивее
В получившейся таблице все-таки не полностью исповедуется подход tidy data – масса указывается с единицами измерения, а линейные размеры вообще все в одной ячейке. Кроме того данные столбцы имеют текстовый формат, что не позволяет корректно сортировать по ним.
pretty_df <- df %>%
#переведем в числовой вид массу, заодно отбросив буквы
mutate(mass = readr::parse_number(Масса, locale = locale(decimal_mark = ","))) %>%
# Уберем скобки и их содержимое, заодно разделим стобцы
mutate(size = stringr::str_replace(`Размеры`,"\\(.*\\)","")) %>%
tidyr::separate(col = size, sep = " x ", into = c("Height","Width","Thickness")) %>%
mutate(Height = readr::parse_number(Height, locale = locale(decimal_mark = ","))) %>%
mutate(Width = readr::parse_number(Width, locale = locale(decimal_mark = ","))) %>%
mutate(Thickness = readr::parse_number(Thickness, locale = locale(decimal_mark = ","))) %>%
# передвинем столбцы в начало
relocate(mass, Height, Width, Thickness, .after = watch)В нашей таблице в колонках каждой характеристики часов (кроме массы и размеров) содержится текстовое описание этой характеристики. Значение почти каждой характеристики понятно и без этого описания.
Было бы удобнее анализировать таблицу просто используя признак TRUE если данная фишка есть в функционале модели. Будем использовать конструкцию ifelse(), а для выбора диапазона столбцов – mutate(across()):
pretty_df <- pretty_df %>%
mutate(across(`Bluetooth® Smart`:`В комплекте: 1 дополнительный браслет`, ~ ifelse(is.na(.x), NA, TRUE)))Выберем нужное
Если нас интересуют только некоторые характеристики, то выберем их через select():
pretty_df <- pretty_df %>%
select(1:6,
contains("gps"),
contains("поиск"),
contains("скорости"),
contains("Высот"),
contains("компас"),
contains("барометр"),
contains("термометр"),
contains("steptracker"),
contains("пульс"))| watch | mass | Height | Width | Thickness | Bluetooth® Smart | GPS измерение скорости-расстояния | Функция поиска телефона | Отображение скорости | Высотометр 10,000 м | Память данных высотометра | График набора высоты | Цифровой компас | Барометр (260 / 1.100 hPa) | Термометр (-10°C / +60°C) | Steptracker | Звуковой сигнал пульсометра | Оптическое измерение пульса |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mr-g/mrg-b2000b-1a4dr/ | 150 | 54.7 | 49.8 | 16.9 | TRUE | NA | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| mr-g/mrg-b5000b-1dr/ | 114 | 49.4 | 43.2 | 12.9 | TRUE | NA | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| mr-g/mrg-b5000d-1dr/ | 114 | 49.4 | 43.2 | 12.9 | TRUE | NA | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| mt-g/mtg-b3000d-1aer/ | 148 | 51.9 | 50.9 | 12.1 | TRUE | NA | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| mt-g/mtg-b3000b-1aer/ | 111 | 51.9 | 50.9 | 12.1 | TRUE | NA | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| mt-g/mtg-b3000bd-1a2er/ | 148 | 51.9 | 50.9 | 12.1 | TRUE | NA | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
В таком виде выбирать часы намного удобнее!:)
Заключение
Эффективность решения задачи зависит от того насколько набита рука и привычных инструментов. Программное решение выгодно тем, что имеющиеся наработки можно использовать повторно.
Проявляйте разумный системный подход и настойчивость)